この記事ではPyTorchで機械学習を始める方向けに、一通りの全体像を抑えられるように、各項目の実践的な実装方法を説明しています。
この記事を読むことで、こんなことがわかります。
- PyTorchを用いたニューラルネットワークのモデルを実装する全体像
- 実戦を意識した各要素の基本的な実装方法
それでは早速、実装の全体像を見ていきましょう。
PyTorchによるモデル作成の全体像
PyTorchに限りませんが、機械学習のモデル作成は基本的に次の要素で構成されます。

それでは、今回使用したライブラリやデータについて簡単に紹介した後、各要素について紹介していきたいと思います。
前提条件
本題に入る前に記事内のコードで使用しているライブラリの一覧とデータについて紹介します。
使用するライブラリ
はじめにこの記事内で使用するライブラリを紹介します。
pytorchでモデル作成する際に使用する最低限のライブラリをImportしています。
ただ、fetch_openmlは今回使用するMNISTデータ取得用なので、独自のデータを用いたい場合は不要です。
from sklearn.datasets import fetch_openml # scikit-learnのデータ取得ライブラリ
import numpy as np
from sklearn.model_selection import train_test_split # Testデータ生成用ライブラリ
import torch # PyTorch
import torch.nn as nn # ニューラルネットワーク生成用ライブラリ
import torch.nn.functional as F # ニューラルネットワーク用の関数
import torch.optim as optim # 最適化関数のライブラリ
使用するデータについて
データはscikit-learnで提供されている手書き数字画像MNISTを利用します。

PyTorchからもMNISTデータは取得できますが、Pytorchの場合Datasetとして取得されます。便利なのですが、DataSetの作成を自作するために、ここではNumpyのarrayで取得できるscikit-learnを利用します。
それでは、実際にfetch_openmlを用いてMNISTデータを取得しましょう。
# Xに画像データ、tに対応する正解ラベル(0~9)が取得されます。
X, t = fetch_openml('mnist_784', version=1, return_X_y=True)
# 取得したデータを確認
print(X.shape, t.shape) # (70000, 784) (70000,)
print(type(X), type(t)) # <class 'numpy.ndarray'> <class 'numpy.ndarray'>
データを確認すると、70,000枚の手書き数字画像がNumpy形式で取得されていることがわかります。
各要素の基本的な実装方法
モデルの構築
データセットとして画像を用いるため、CNNモデルの構築を例にモデル構築について見ていきます。
今回構築するCNNモデルはこのようになっています。
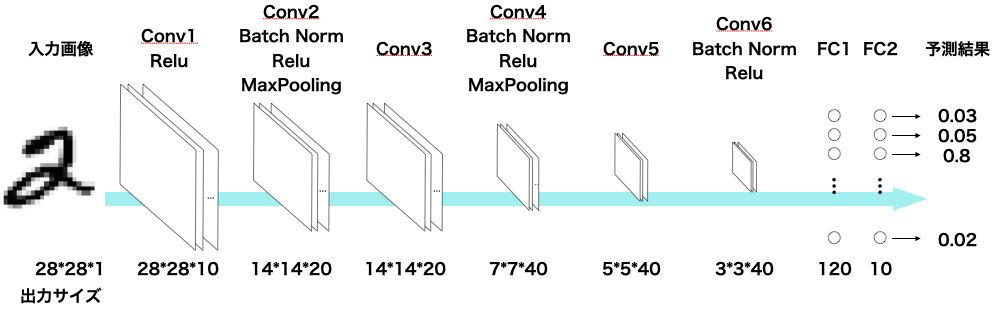
このCNNモデルをPyTorchで実装したのが次のコードです。
PyTorchでは、NNの各層の定義をコンストラクタ(__init__)で行い、順伝播の処理をforwardメソッドに記載します。
class Model(nn.Module):
# 使用するニューラルネットの層を定義していきます。
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(10, 20, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(num_features=20)
self.conv3 = nn.Conv2d(20, 20, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(20, 40, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(num_features=40)
self.conv5 = nn.Conv2d(40, 40, kernel_size=3, padding=0)
self.conv6 = nn.Conv2d(40, 40, kernel_size=3, padding=0)
self.bn3 = nn.BatchNorm2d(num_features=40)
self.fc1 = nn.Linear(40 * 3 * 3, 120) # 6*6 from image dimension
self.fc2 = nn.Linear(120, 10)
# __init__で定義した層を用いて、順伝播の処理を記載していきます。
def forward(self, x):
# import pdb; pdb.set_trace()
x = F.relu(self.conv1(x))
x = F.max_pool2d(F.relu(self.bn1(self.conv2(x))), (2,2))
x = F.relu(self.conv3(x))
x = F.max_pool2d(F.relu(self.bn2(self.conv4(x))), (2,2))
x = F.relu(self.conv5(x))
x = F.relu(self.bn2(self.conv6(x)))
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
CNNモデルアーキテクチャの図とforwardメソッドを見比べることで、CNNモデルの実装方法が見えてくるかと思います。
損失関数と評価関数の設定
次に、損失関数と評価関数を設定していきます。
今回は損失関数にCrossEntropyLoss、評価関数にAdamを使用します。
PyTorchで実装されている損失関数と評価関数をそれぞれリンクから確認できます。
# 損失関数の定義
criterion = nn.CrossEntropyLoss()
# 評価関数の定義
# 最適化関数(optimizer)の定義
# 第一引数にoptによって最適化するパラメータ群を指定する。モデルのパラメータ群になるはず。
lr = 1e-3
opt = optim.Adam(model.parameters(), lr=lr)
DataSetの実装
モデルに入力するデータを作成するDataSetクラスとDataLoaderクラスについて説明します。
DataLoaderクラスはDataSetを繰り返し呼ぶ事で、モデルに入力するDataSet(画像データと正解ラベル)を順番に取得します。
DataSetクラスでは、DataLoaderによって呼ばれたときに、モデルに入力するDataSet(画像データと正解ラベル)を1セットずつ渡すように実装します。
この処理を実現するためにDatasetクラスでは、__init__、__len__、__getitem__ の3つのメソッドを作成していきます。
※厳密には__iter__()を実装する方法もあります。詳しく知りたい方はこちらの公式ドキュメントのリンクを参照ください。
class MyDataset(torch.utils.data.Dataset):
def __init__(self, dataset):
super(MyDataset, self).__init__()
self.dataset = dataset
# データセットの数
def __len__(self):
return len(self.dataset[0])
# DataLoaderに呼ばれた際に取得するデータセット
def __getitem__(self, idx):
# idx単位で取得するようにするのがポイントな気がする。__getitem__として動作させるには。
x = self.dataset[0][idx]
label = self.dataset[1][idx]
x = x[np.newaxis,:,:].astype(np.float32) / 255
return x, label
これによってDataSetクラスは、例えばDataLoaderからの呼び出しに対して、idx番目の画像データと正解ラベルのセットを取得します。
学習・評価用データセットの作成
DataSetクラスを作成したので、データセットとDataLoaderを作成します。
学習と評価には異なるデータを使用するためDataSetとDataLoaderもそれぞれ別に作成しています。
ポイントとして学習用のDataLoaderでは、Epochごとにデータを入力する順番をシャッフル(shuffle=True)する事で、入力順が学習に影響しないようにしています。
# 学習用のデータセット
train_dataset = MyDataset([train_X, train_t])
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=4,shuffle=True, num_workers=1)
# 評価用のデータセット
test_dataset = MyDataset([test_X, test_t])
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=4, shuffle=False, num_workers=1)
モデルの学習
入力するデータセット、モデル構造、損失関数・評価関数の準備ができましたので、次はモデルを学習していきます。
モデル学習の基本的な流れは次の通りです。
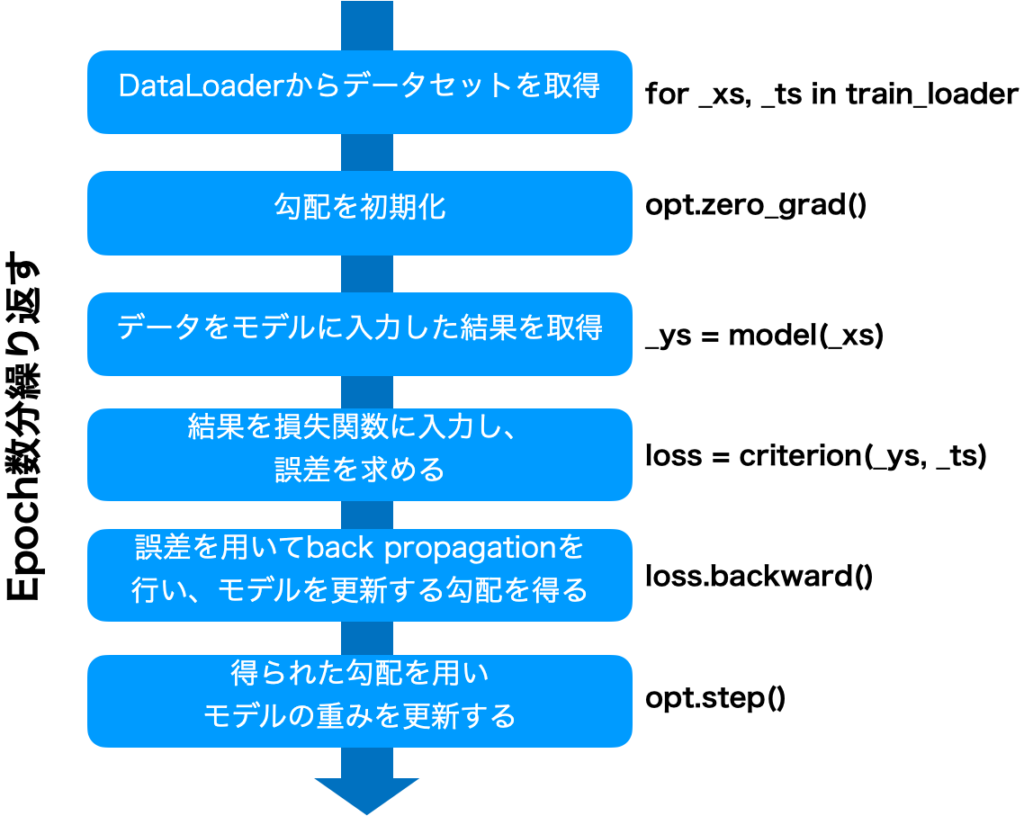
上記は、モデル学習の流れになりますが、実際はモデルを学習する処理(Training)と学習したモデルを評価する処理(Evaluation)を連続して行います。この1回の流れの単位をepoch(エポック)と呼びます。
それでは実際のコードを見ていきましょう。
best_loss = 1e5 # 誤差の初期値
n_epochs = 10 # エポック数
for epoch in range(1, n_epochs):
print(f'Epoch = {epoch: 03d}')
model.train()
train_loss = 0
# Training
for _xs, _ts in train_loader:
_xs, _ts = _xs.to(device), _ts.to(device)
# stack overflow
# https://stackoverflow.com/questions/48001598/why-do-we-need-to-call-zero-grad-in-pytorch
opt.zero_grad() # 勾配を初期化
_ys = model(_xs)
loss = criterion(_ys, _ts)
train_loss += loss.item()
# back propagation
loss.backward() # モデルの勾配を計算
opt.step() # モデルのパラメータを更新
_xs = _xs.to('cpu').detach().numpy()
_ts = _ts.to('cpu').detach().numpy()
train_loss /= len(train_loader)
# Evaluation
model.eval()
valid_loss = 0
# 評価の場合は勾配を保存しないように設定
with torch.no_grad():
ts, ys = [], []
for _xs, _ts in test_loader:
_xs, _ts = _xs.to(device), _ts.to(device)
_ys = model(_xs)
valid_loss += criterion(_ys,_ts)
ys.append(_ys.to('cpu').detach().numpy())
ts.append(_ts.to('cpu').detach().numpy())
ys = np.concatenate(ys, axis=0)
valid_loss /= len(test_loader)
# 評価時の誤差関数の結果が一番小さいモデルを保存する
if valid_loss <= best_loss:
torch.save(model.state_dict(), './model_00.pt')
best_loss = valid_loss
# 学習状況の確認。学習時、評価時、一番良い誤差を出力。
print(f'Loss Train={train_loss:.4f}, Test={valid_loss:.4f}, Best={best_loss:.4f}')
これによって学習したモデルを取得することができました。
では最後に、この作成したモデルを使って実際に手書き文字を読み取らせてみましょう。
モデルを使用して推論する
学習したモデルにデータを入力して結果を得ることを推論すると呼びます。
ここまでで作成したモデルを使って、手書き数字の画像を実際に推論します。
推論の手順は学習と比べるとずっとシンプルです。
- 学習したモデルのLoad
- 推論する画像をモデルに入力
- モデルの出力結果を元に0〜9のクラスに分類
# モデルのLOAD
# 公式サイト:https://pytorch.org/tutorials/beginner/saving_loading_models.html
model.load_state_dict(torch.load('./model_00.pt'))
model.eval()
# 推論する画像の表示(確認用に表示しています。)
input_id = 0
_x = test_X[input_id,:,:].astype(np.float32) /255
fig, ax = plt.subplots()
ax.axes.xaxis.set_visible(False) # X軸を非表示にする
ax.axes.yaxis.set_visible(False) # Y軸を非表示にする
ax.imshow(_x, cmap='Greys')
# 推論する画像をモデルに入力
_x = torch.from_numpy(_x[np.newaxis, np.newaxis,:,:]).clone() # 推論するためにndarray型のデータをTensor型に変換。
_x = _x.to(device) # GPUに載せる
_y = model(_x) # 推論
_y = _y.to('cpu').detach().numpy() # CPUに載せて、Tensor型からndarray型へ
# 推論結果を元にクラス分類
pred = np.argmax(_y, axis=1)
# 推論結果の表示
print(f'推論結果:{pred}')

推論結果が「1」となっており、ちゃんとモデルが学習され手書き文字画像を読み取れることがわかりました。
実際にはこのモデルの精度は約99%なので、100枚に1枚は間違っていると思います。
終わりに
PyTorchを用いて機械学習のモデルを構築する方法を紹介しました。
手書き文字画像のMNISTというシンプルな画像を用いましたが、実践する上での基本的な流れは紹介できたと思っています。
より実践的な画像を用いる場合はデータの前処理や、Datasetの処理、モデルアーキテクチャを工夫していくことになりますので、そのあたりの技術も紹介していきたいと思います。
それではまた、ここまで読んでいただきありがとうございます。
コード全文
google colaboratoryで実行できるコードをあげておきます。
<pre class="wp-block-syntaxhighlighter-code">
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import cv2
from google.colab.patches import cv2_imshow
%matplotlib inline
X, t = fetch_openml('mnist_784', version=1, return_X_y=True)
print(X.shape, t.shape)
print(type(X), type(t))
# ラベルを文字列から数値に変換
t = np.array([int(val) for val in t])
# Train test split
trainX_inds, testX_inds, train_t_inds, test_t_inds = train_test_split(range(len(X)), range(len(t)), test_size=0.2, random_state=1000, shuffle=1000)
X = X.values.reshape([X.shape[0],28,28])
train_X = X[trainX_inds]
test_X = X[testX_inds]
train_t = t[train_t_inds]
test_t = t[test_t_inds]
# 単位行列を利用したOne-Hot変換
# https://note.nkmk.me/python-numpy-eye-identity-one-hot/
e = np.eye(10)
train_t_hot = e[train_t]
test_t_hot = e[test_t]
fig, axes = plt.subplots(nrows=2, ncols=3)
for i in range(0,6):
row = i % 2
col = i // 2
axes[row, col].axes.xaxis.set_visible(False)
axes[row, col].axes.yaxis.set_visible(False)
axes[row, col].imshow(X[i], cmap='Greys')
# model.py
# オリジナルのCNNモデル
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(10, 20, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(num_features=20)
self.conv3 = nn.Conv2d(20, 20, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(20, 40, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(num_features=40)
self.conv5 = nn.Conv2d(40, 40, kernel_size=3, padding=0)
self.conv6 = nn.Conv2d(40, 40, kernel_size=3, padding=0)
self.bn3 = nn.BatchNorm2d(num_features=40)
self.fc1 = nn.Linear(40 * 3 * 3, 120) # 6*6 from image dimension
# self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(120, 10)
# 必須。順伝播の処理のforwardメソッドをOverrideする
def forward(self, x):
# import pdb; pdb.set_trace()
x = F.relu(self.conv1(x))
x = F.max_pool2d(F.relu(self.bn1(self.conv2(x))), (2,2))
x = F.relu(self.conv3(x))
x = F.max_pool2d(F.relu(self.bn2(self.conv4(x))), (2,2))
x = F.relu(self.conv5(x))
x = F.relu(self.bn2(self.conv6(x)))
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
# x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
model = Model()
# lossの定義
criterion = nn.CrossEntropyLoss()
# 評価関数の定義
# 最適化関数(optimizer)の定義
# 第一引数にoptによって最適化するパラメータ群を指定する。NNのパラメータ群になるはず
lr = 1e-3
opt = optim.Adam(model.parameters(), lr=lr) # TODO コードを確認
class MyDataset(torch.utils.data.Dataset):
def __init__(self, dataset):
super(MyDataset, self).__init__()
self.dataset = dataset
def __len__(self):
return len(self.dataset[0])
def __getitem__(self, idx):
# idx単位で取得するようにするのがポイントな気がする。__getitem__として動作させるには。
x = self.dataset[0][idx]
label = self.dataset[1][idx]
x = x[np.newaxis,:,:].astype(np.float32) / 255
label = label.astype(np.int32)
return x, label
# データセット作成
train_dataset = MyDataset([train_X, train_t])
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=4,shuffle=True, num_workers=1)
test_dataset = MyDataset([test_X, test_t])
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=4, shuffle=False, num_workers=1)
device = torch.device('cuda')
model = model.to(device)
# Training
best_loss = 1e5
n_epochs = 3
for epoch in range(1, n_epochs+1):
print(f'Epoch = {epoch: 03d}')
model.train()
train_loss = 0
# Training
for _xs, _ts in train_loader:
_xs, _ts = _xs.to(device), _ts.to(device)
opt.zero_grad() # 勾配を初期化
_ys = model(_xs)
loss = criterion(_ys, _ts)
train_loss += loss.item()
# back propagation
loss.backward() # 勾配の計算
opt.step() # パラメータの更新
_xs = _xs.to('cpu').detach().numpy()
_ts = _ts.to('cpu').detach().numpy()
train_loss /= len(train_loader)
# Evaluation
model.eval()
valid_loss = 0
with torch.no_grad():
ts, ys = [], []
for _xs, _ts in test_loader:
_xs, _ts = _xs.to(device), _ts.to(device)
_ys = model(_xs)
valid_loss += criterion(_ys,_ts)
ys.append(_ys.to('cpu').detach().numpy())
ts.append(_ts.to('cpu').detach().numpy())
ys = np.concatenate(ys, axis=0) # TODO この処理が必要か確認
valid_loss /= len(test_loader)
if valid_loss <= best_loss:
torch.save(model.state_dict(), './model_00.pt')
best_loss = valid_loss
print(f'Loss Train={train_loss:.4f}, Test={valid_loss:.4f}, Best={best_loss:.4f}')
results = np.argmax(ys, axis=1)
# Validation結果確認
print(t[test_t_inds][:30])
print(results[:30])
n_correct = results == t[test_t_inds]
accuracy = n_correct.sum() / len(results)
print(f'Accuracy= {accuracy:.4f}')
# モデルのLOAD
model.load_state_dict(torch.load('./model_00.pt'))
model.eval()
# 推論する画像の表示
input_id = 0
_x = test_X[input_id,:,:].astype(np.float32) /255
fig, ax = plt.subplots()
ax.axes.xaxis.set_visible(False) # X軸を非表示にする
ax.axes.yaxis.set_visible(False) # Y軸を非表示にする
ax.imshow(_x, cmap='Greys')
# モデルを用いてデータを推論
_x = torch.from_numpy(_x[np.newaxis, np.newaxis,:,:]).clone() # 推論するためにndarray型のデータをTensor型に変換。
_x = _x.to(device) # GPUに載せる
_y = model(_x) # 推論
_y = _y.to('cpu').detach().numpy() # CPUに載せて、Tensor型からndarray型へ
pred = np.argmax(_y, axis=1)
# 推論結果の表示
print(f'推論結果:{pred}')
</pre>

コメント