
この記事では日々進化し続けるAI技術のうち、DeepLearningを用いた画像識別系のAIタスクについて具体的なアーキテクチャと共に概要を説明します。社会のニーズに合わせてAIタスクも細分化され、多種多様なタスクがありますが代表的なものに限定し、ポイントを絞った記事にします。
物体検出(Object Detection)
画像に写っている人や物を検出するタスクが物体検出です。物体の位置を検出(Localization)しバウンディングボックスと呼ばれる矩形で囲み、囲まれた物体が何かを分類(Classification)します。
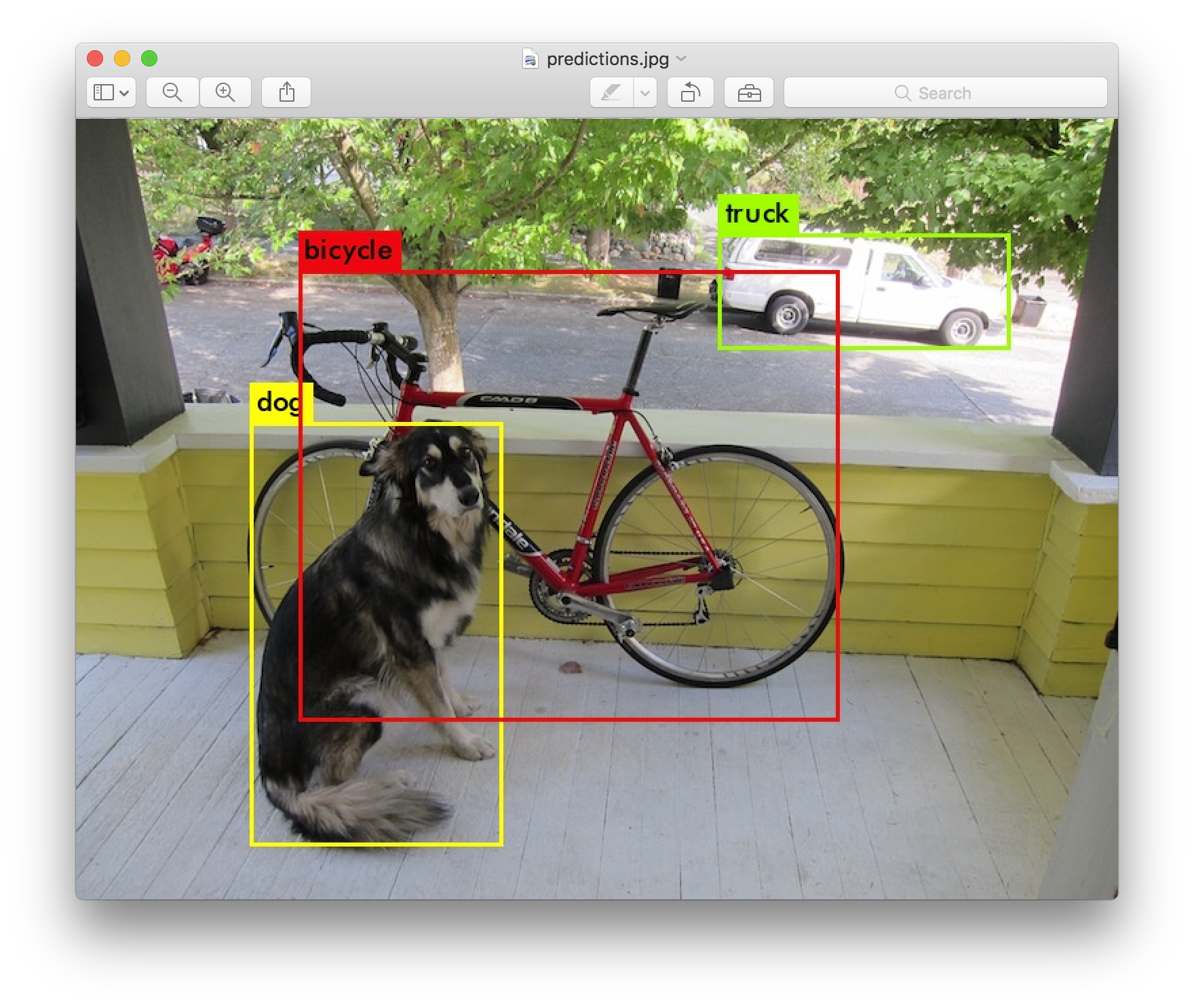
概要
物体検出のアーキテクチャは大きく2種類あり、YOLOやSSDに代表されるone-stage型と、Faster RCNNやに代表されるtwo-stage型があります。
- two-stage
- Selective Search(R-CNN, Fast R-CNNの場合)やRegion Proposal Network(Faster F-CNNの場合)という領域候補を生成する処理と、領域候補に対して物体分類(Classification)を行う処理の2段構成
- 領域検出と分類を
- 代表的なアーキテクチャ:R-CNN(Region based CNN), Fast R-CNN, Faster R-CNN
- one-stage
- 領域候補を生成せずに、物体分類とバウンディングボックス作成を同時に実施
- 代表的なアーキテクチャ:YOLO(You Only Look Once), SSD(Single Shot Detection)
- 特徴:処理がシンプルで比較的高速
代表的なアーキテクチャ
Faster R-CNN
two-stage型の代表的なアーキテクチャがR-CNNです。名前から分かる通り、Faster R-CNNはR-CNNを高速化したFast R-CNNをさらに高速化したアーキテクチャです。R-CNNは大まかに言うと、
- 物体が存在する領域候補(Region Proposal)を生成
- 生成された各領域に対して画像分類
という2ステップを取ります。
R-CNNではselective searchというアルゴリズムを用い画像あたり最大2000ヶ所の領域候補を生成し、各領域候補に対してCNNで特徴抽出を行って画像分類するため、膨大な計算量になりました。ここではR-CNNの改良版のFaster R-CNNについて取り上げます。
Faster R-CNNの全体概要を元論文を引用しつつ説明します。
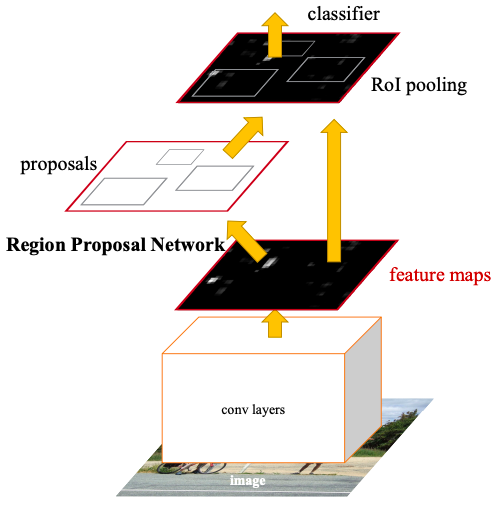
構成要素としては、
- 特徴マップの生成:入力画像をconv layers(VGG16やZFNetなど)に食わせて特徴マップ(feature maps)を生成します。
- 領域候補(Region proposal)の推定:feature mapsをRegion Proposal Network(RPN)に入力し領域候補を推定します。
- RoI Pooling:推定した領域候補の範囲を特徴マップから抽出し、RoI Poolingによって固定サイズに変換します。
- クラス分類:RoI Poolingによって固定サイズに変換された特定領域の特徴マップに対して、分類器(classifier)によってクラス分類します。
があります。そのためFaster R-CNNを学習する場合は、RPNの学習とクラス分類器の学習を行うことになります。
YOLO
one-stage型のアーキテクチャとしてはSSDやYoloが有名ですが、ここでは引き続きアップデートが盛んなYoloについて紹介したいと思います。
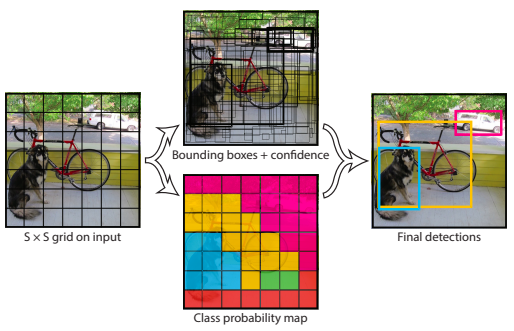
YOLOの特徴を簡潔に述べると以下になります。
- 物体検出のコンポーネントを1つに統合
- R-CNNで2段階に分かれていた領域候補の検出と分類を1つに統合し、画像全体の特徴を用いてBounding Box(BBox)とクラス分類を同時に実施
- これにより高精度な検出を維持しつつend-to-end学習とリアルタイムな検出スピードを実現
- グリッドセルの採用
- 入力画像をS×Sのグリッドに分割し、各グリッドに、物体の中心がグリッド内に位置する物体を検出する責任を持たせる
- グリッドセルは複数のBBoxを持つ(論文では2つ)
- 各グリッドはBBoxの数に関わらず1つセットのクラス確率を持つ。つまり、グリッド毎に推論されるクラスは1つのみ。
- YOLOの出力
- YOLOはグリッドセル毎に、BBoxのConfidence、BBoxの位置情報(X, Y, H, W)、クラス毎の予測確率を出力する。
- 例えば、グリッドセルS=7、グリッド毎のBBox数B=2、クラス数C=20の場合の出力サイズは、S×S×(B*(1+4)+C)=7×7×30
- Confidence( = Pr(Object) * IOUTruthPred):BBoxに物体が含まれているかと、BBoxの予測がどの程度正しいかの信頼度
- BBoxの位置情報(X, Y, H, W):
- X, Y:グリッドセルの境界を基準としたBBoxの中心座標
- W, H:画像全体に対する相対値
こちらが論文で紹介されているYOLOのアーキテクチャです。入力として448×448のカラー画像(3次元)を受け取り、出力として7×7×30のグリッド毎の物体検出結果を出します。
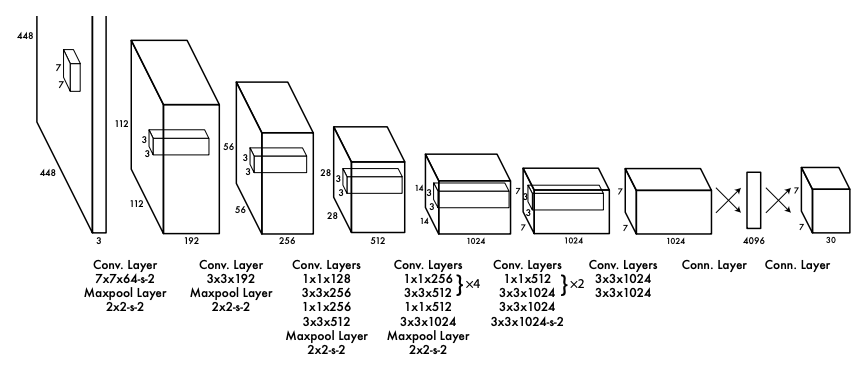
参考リンク
[stack overflow]One stage vs two stage object detection
[Qiita]物体検出についてのまとめ(1)
[Medium]What do we learn from region based object detectors (Faster R-CNN, R-FCN, FPN)?
[Qiita]物体検出Faster R-CNN (Faster Region-based CNN)
物体検出の代表アルゴリズム YOLOシリーズを徹底解説!【AI論文解説】
セグメンテーション(Segmentation)
物体検出では矩形で画像内に存在する物体を検出していましたが、Segmentationでは画像のピクセル単位で分割します。Segmentationは大きく3種類のタスクに分類され、アーキテクチャの複雑さもタスク毎に変わるため用途に合わせて適切なアーキテクチャを選択する必要があります。
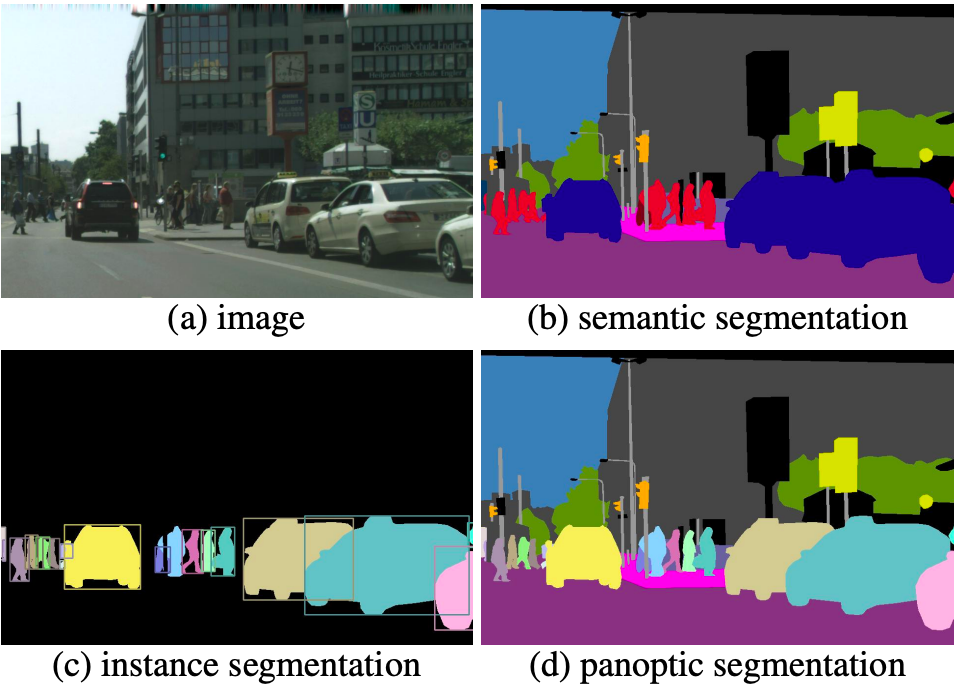
概要
- Semantic Segmentation
- 画像内の各ピクセルに対して、該当ピクセルがどのクラス(人、車、建物など)に分類されるかを推論する。同じクラス同士の区別をしないため、人や車が複数写っていてもそれぞれ人、車というクラスに分類される。
- 特徴
- セグメンテーションの中で最もシンプルなタスクであり、アーキテクチャも比較的わかりやすい。
- 同じクラス同士での区別がされず、境界も分からない。
- 代表的なアーキテクチャ:FCN(Fully Comvolutional Network), U-Net
- Instance Segmentation
- セマンティックセグメンテーションと物体検出を組み合わせ、インスタンス(物体)単位でのセグメンテーション(領域分割)を実現するタスク。
- 特徴
- インスタンスを区別するため、重なり合っている場合でも境界を認識できる。
- 代表的なアーキテクチャ:Mask R-CNN,
- Panoptic Segmentation
- Panopticの意味は“including everything visible in one view"(論文より引用)
- セマンティックセグメンテーションとインスタンスセグメンテーションを組み合わせたタスク。インスタンスだけでなく、背景といった物体検出でインスタンスとして検出されない範囲もセグメンテーション対象。
- 特徴
- Panoptic("全面的な"という意味)の名前の通り画像内の全てを対象とし、インスタンスも区別しつつセグメンテーションを行う
- 画像全体のセグメンテーションと物体検出を行うため、セグメンテーションタスクの中で最も重たい
- 代表的なアーキテクチャ:Efficient Panoptic Segmentation
Mask R-CNN
Mask R-CNNはFacebookのAI研究チームによって発表されました。Faster F-CNNに簡易なレイヤーを追加するだけでセグメンテーション機能を実現しています。
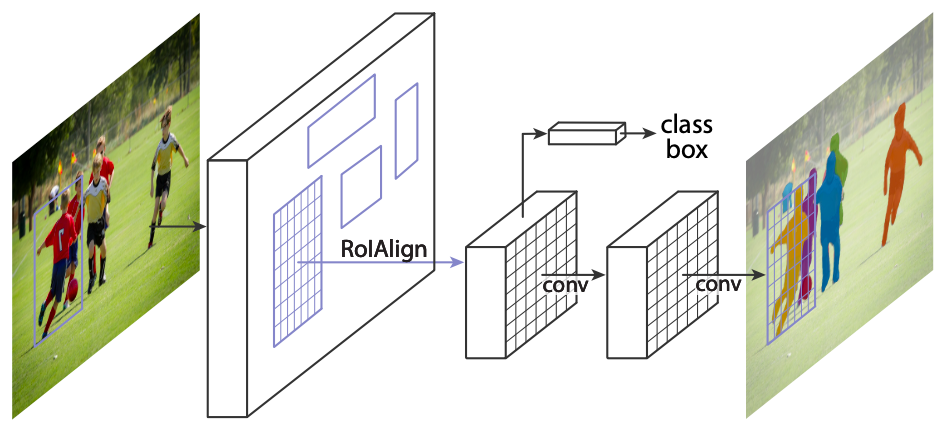
Faster R-CNNにおける既存の物体検出/クラス分類ブランチと並行して、各RoI(画像中の注目領域)におけるセグメンテーションマスクを生成するブランチを処理します。ベースのFaster R-CNNの仕組みを流用しつつ、さらに追加のマスクブランチもCNNを2つ追加するだけの簡易な構成で、セグメンテーションへの拡張を実現しています。
また、Mask R-CNNではRoIを特定するアルゴリズムを改善したRoI Alignが提案されており、位置情報の精度向上に貢献しています。
参考リンク
Image segmentation with Mask R-CNN
[Paper]EfficientPS: Efficient Panoptic Segmentation
終わりに
AIによる画像認識のうち最も定番なタスクである物体検出とセグメンテーションについて、概要と代表的なアーキテクチャを紹介しました。次はビジネスにおいても頻繁に登場する異常検知、姿勢推定、顔認証といったタスクについて紹介していきたいと思います。


コメント