データ分析を効率的に実施するために、毎回実施する定番手法を流れに沿って紹介していきます。
執筆にあたり、kaggleのHousePriceコンペティションでデータ分析ジャンルとして100を超える評価を獲得したNoteBookを参考にまとめています。
それでは順番にデータ分析手法を紹介していいます。
データ分析の定番手法
- データの生値を確認する
- Numerical(数値)変数の一覧を確認する
- カテゴリカル変数の一覧を確認する
- データの統計量(平均、分散など)を一覧で確認する
- 欠損値の確認
- 外れ値の分析
- よく使われる統計指標の確認
今回参考にさせていただいたkaggle notebookはこちらです。
どちらもデータ分析として多くのVoteを集めていた(片方はkaggle Master)ので勉強になると思います。
それでは具体的にコードと出力結果とともに紹介していきたいと思います。
データの生値を確認する
早速データを読み込んでいきます。HousePriceコンペでは住宅価格がCSVデータで提供されているのでPandasのread_csvで読み込みます。
# 必要なライブラリをImport
import numpy as np #
import pandas as pd # CSVファイルの読み込みから分析に利用
import seaborn as sns # データの可視化に利用
import matplotlib.pyplot as plt
# データの読み込み
df_train = pd.read_csv("../input/train.csv")
# データサイズを確認する
print(df_train.shape)
# 生データを確認する
# 表示したい行数をhead()で指定する。デフォルトは5行
df_train.head(6)

どういうデータが与えられているかざっくり分かったので、内訳を確認していきます。
Numerical(数値)変数の一覧を確認する
生データを確認するとNumerical変数(数値で与えられているデータ)と、カテゴリカル変数(血液型でいうA型、B型のような数値ではないデータ)で与えられていることがわかります。なので順番にどんな変数があるか一覧でみていきます。
numeric_features = df_hp.select_dtypes(include=[np.number])
print(numeric_features.columns)
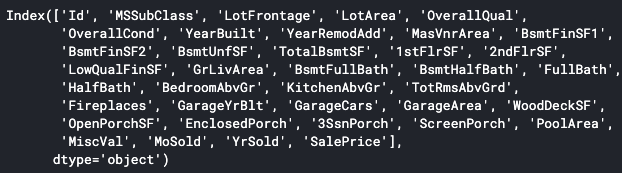
select_dtypesメソッドを使うことで特定のデータタイプ(dtype)のデータだけを取得できます。includeで指定すると指定したデータタイプのみが、excludeで指定すると指定のタイプ以外が対象となります。ちなみにnp.numberとすることで数値の型を全て対象にできます。
カテゴリカル変数の一覧を確認する
同じようにカテゴリカル変数の一覧を確認します。
categorical_features = df_hp.select_dtypes(exclude=[np.number])
print(categorical_features.columns)

データの統計量(平均、分散など)を一覧で確認する
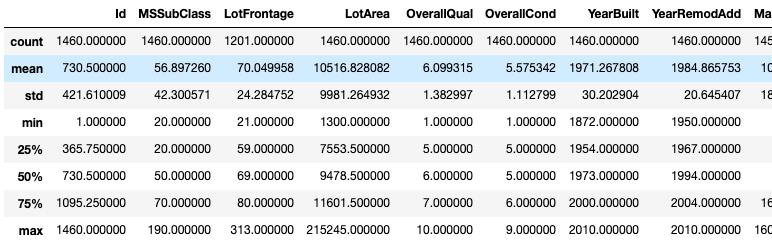
PandasのDataFrame使用している場合、describeメソッドを用いることで、統計量の一覧を簡単に確認することができます。
# 統計量のサマリーを確認する
df_train.describe()
欠損値の確認
それぞれの変数に対して全てデータがあるとは限りません、例えば家に面している路地(alley)の情報はないかもしれません。
このような欠損値の有無はデータ処理する際に重要な情報になるため有無を確認します。
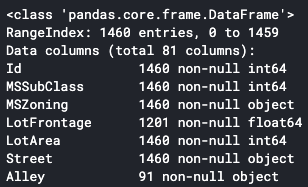
# info()メソッドを使った確認方法
print(df_hp.info())
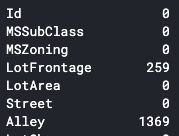
# isnull()メソッドを使った確認方法
print(df_hp.isnull().sum())
ここでは2つの確認方法を上げました。info()メソッドではNullではないデータの数が表示されます。isnull()メソッドを使った方法ではNull値の数が表示されます。どちらでも必要なことはわかるため、好きな方を用いれば良いかと思います。
外れ値の分析
外れ値は平均や分散などの統計情報からの分析を難しくしますし、機械学習を用いる場合は期待通りの学習がされないなどの問題が生じますので、分析により見つけることが大事です。
外れ値を分析するために、散布図とBox Plotを用いてデータを可視化していきます。コードはこちらのnotebookを参照しています。
var = 'TotalBsmtSF'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
f, ax = plt.subplots(figsize=(6, 4))
# fig = sns.boxplot(x=var, y="SalePrice", data=data)
fig = sns.regplot(x=var, y = 'SalePrice',data = data,scatter= True, fit_reg=True, ax=ax)
fig.axis(ymin=0, ymax=800000);
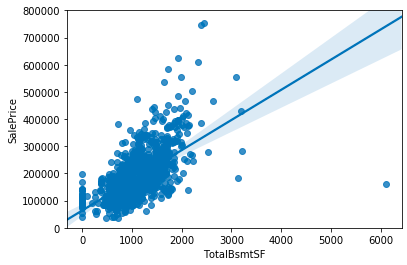
TotalBsmtSF=6000において、明らかに外れている値があることがわかります。
var = 'OverallQual'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
f, ax = plt.subplots(figsize=(12, 8))
fig = sns.boxplot(x=var, y="SalePrice", data=data)
fig.axis(ymin=0, ymax=800000);
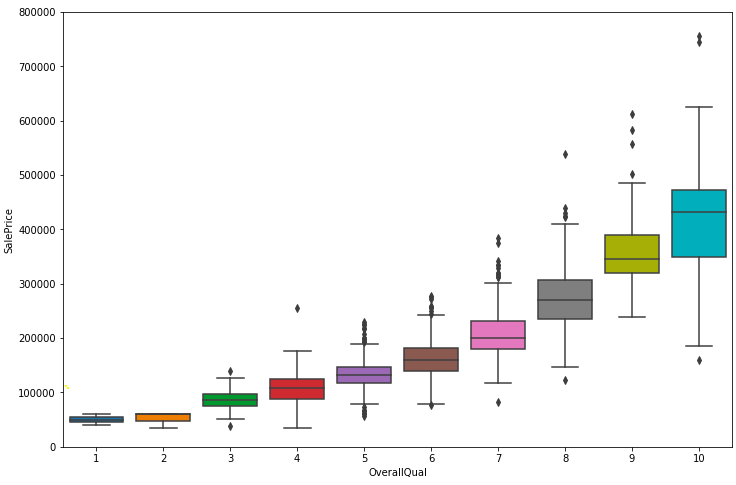
よく使われる統計指標の確認
最後によく用いられる統計指標として、尖度と歪度の分析を行います。
尖度と歪度についてはこちらのサイトの説明が分かりやすかったですが、ざっくりいうと、
尖度とは対象の分布が正規分布と比較してどのくらい尖っているか、
歪度とは対象の分布が正規分布と比較してどのくらい左右に歪んているか、
を示す指標になります。
# Numerical変数の尖度と歪度を確認する
for col in numeric_features.columns:
print(f'{col:15} Skewness:{df_train[col].skew():5.2f}, Kurtosis: {df_train[col].kurt():5.2f}')
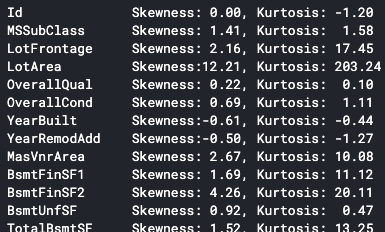
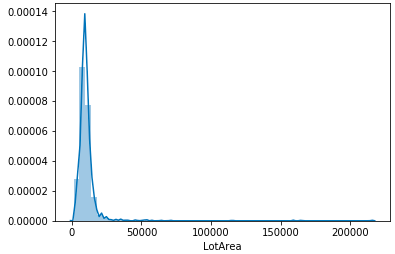
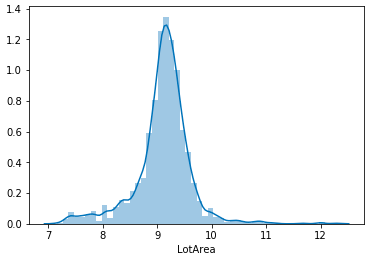
LotAreaの尖度と歪度が大きいことがわかります。試しにグラフを確認すると分布は鋭いピークが左側に寄っており、裾が長いことがわかります。
sns.distplot(df_train['LotArea'])
参考までに機械学習を行う場合は、対数(Log)を取った変数を代わりに使用した方が上手くいくことが多いです。
print(f'Skewness:{np.log(df_train["LotArea"]).skew():5.2f}, Kurtosis: {np.log(df_train["LotArea"]).kurt():5.2f}')
sns.distplot(np.log(df_train['LotArea']))

対数を取ることで尖度と歪度が小さくなっており、グラフからもその様子が確認できます。
終わりに
CSVデータの分析手法をkaggle notebook元に書きましたが、ヒートマップを使った相関分析や、Pair Plotを用いた散布図の概要分析など、今回紹介しきれなかった手法がまだまだありますので、少しずつ更新していきたいと思います。


コメント